Unlock Your Notes: Build a Personal AI Assistant with This Open-Source Course
Imagine asking complex questions directly to your scattered digital notes, research articles, and personal knowledge base, getting synthesized, relevant answers instantly. That’s the promise of a ‘Second Brain’ AI assistant, and a new open-source course aims to teach you exactly how to build one.
Decoding ML has launched the first lesson of their free, six-part course: Building Your Second Brain AI Assistant Using Agents, LLMs and RAG. This isn’t just theory; it’s a hands-on journey guiding you through the architecture and implementation of a production-ready, Notion-like AI research assistant that talks directly to your digital resources.
What You’ll Build and Learn
The goal is to create an AI assistant capable of querying your knowledge stored in apps like Notion, Obsidian, or Evernote, providing answers grounded only in your curated information, thus minimizing hallucination. Think of it like Google’s NotebookLM or Notion’s own AI features, but personalized and built by you.
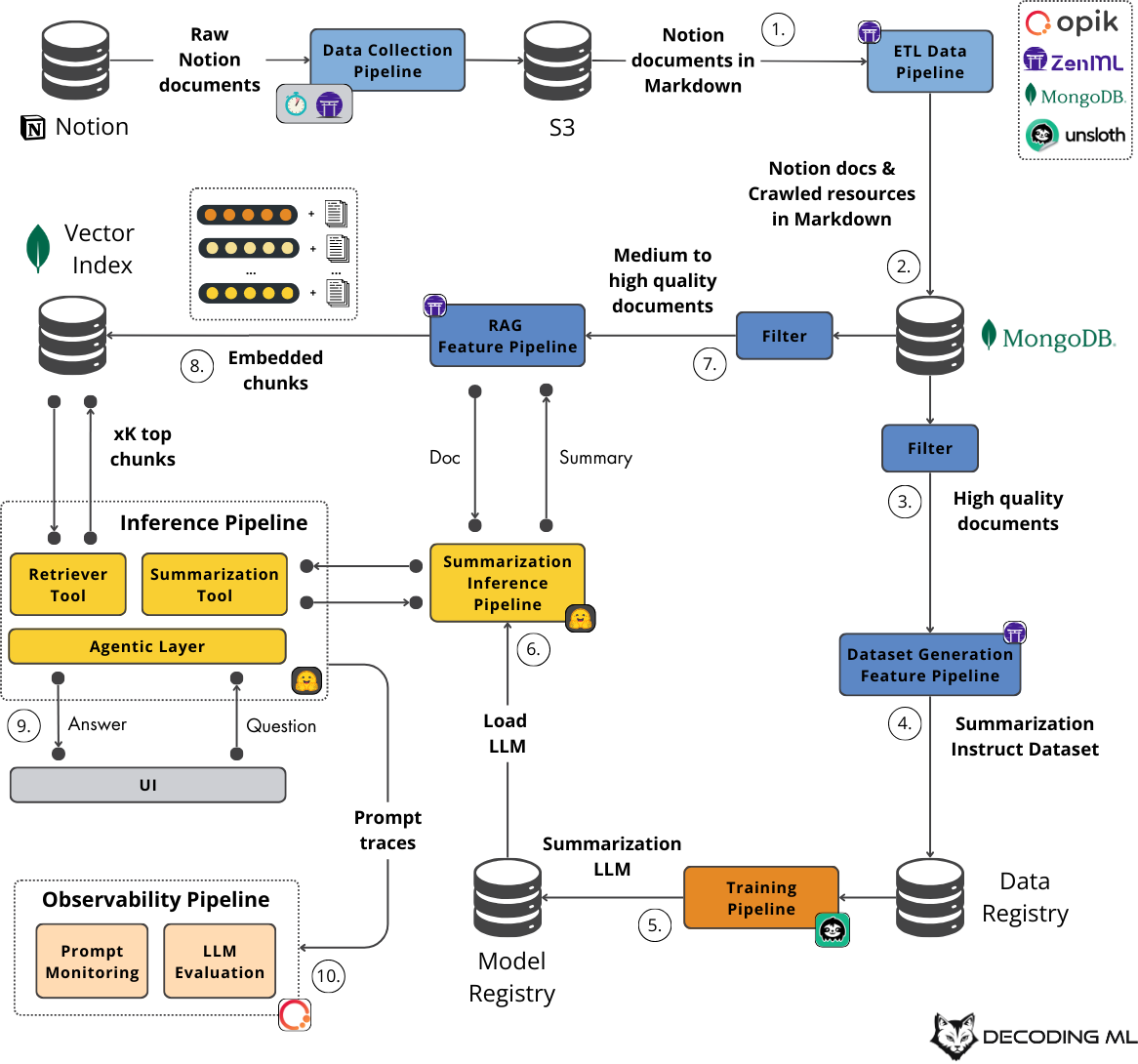
Throughout the course, you’ll dive deep into the essential components of modern AI applications:
- AI System Architecture: Designing robust systems using the Feature/Training/Inference (FTI) pattern, distinguishing between offline (batch) and online (real-time) pipelines.
- Data Pipelines: Collecting data (e.g., from Notion API), crawling embedded links (using Crawl4AI), normalizing content to Markdown, computing quality scores with LLMs, and storing data efficiently (using MongoDB).
- Advanced RAG: Implementing cutting-edge Retrieval-Augmented Generation techniques beyond naive approaches, including Contextual Retrieval and hybrid search, using vector databases like MongoDB Atlas Vector Search.
- LLM Fine-tuning: Generating specialized instruction datasets (via distillation) from your own documents and fine-tuning open-source models like Llama 3.1 8B (using Unsloth) for specific tasks like summarization needed within the RAG pipeline.
- Agentic Systems: Building AI agents (using frameworks like Hugging Face’s smolagents) that can utilize multiple tools (like retrieval and summarization) to answer complex queries.
- LLMOps & MLOps: Incorporating best practices, including data/model registries (Hugging Face), experiment tracking (Comet), pipeline orchestration (ZenML), prompt monitoring, and RAG evaluation (Opik).
- Software Engineering: Applying solid software engineering principles with tools like
uvandruff.
The course emphasizes building intuition by implementing components from scratch where valuable, while also showing how to integrate and extend existing frameworks like LangChain when practical.
The Architecture Blueprint
The course meticulously details the system architecture, breaking it down into logical pipelines:
- Data Pipelines (Offline): Collect, clean, standardize, crawl links, score quality, and load data into MongoDB.
- Feature Pipelines (Offline): Prepare data for RAG (chunking, embedding, loading to MongoDB Vector Search) and generate a fine-tuning dataset (distillation, saving to HF Hub).
- Training Pipeline (Offline): Fine-tune the LLM using the generated dataset and save the model to HF Hub. ZenML orchestrates these offline steps.
- Inference Pipelines (Online):
- Deploy the fine-tuned summarization model (e.g., via HF Dedicated Endpoints).
- Run the main agentic RAG application, which takes user queries, uses tools to retrieve from the vector DB and summarize, and generates answers. Includes a Gradio UI for interaction.
- Observability Pipeline (Online): Monitor prompts and evaluate the RAG system using Opik.
This clear separation between offline data preparation/training and online serving/monitoring reflects real-world production systems.
Summary & Key Takeaways
This open-source course offers developers a comprehensive, practical guide to building sophisticated, personalized AI assistants. Key takeaways include:
- End-to-End Learning: Covers the entire lifecycle from data collection and processing to model fine-tuning, advanced RAG implementation, agent creation, deployment, and observability.
- Production Focus: Emphasizes building robust, production-ready systems using industry best practices and modern tooling (MLOps/LLMOps).
- Hands-On Approach: Balances building from scratch for deeper understanding with leveraging existing frameworks effectively.
- Personalized AI Power: Demonstrates how to make your own knowledge base interactive and queryable using state-of-the-art AI techniques.
Related Resources
- Full Course on GitHub: https://github.com/decodingml/second-brain-ai-assistant-course
- Decoding ML Blog: https://decodingml.substack.com/
- ZenML (Orchestration): https://zenml.io/
- MongoDB Atlas Vector Search: https://www.mongodb.com/products/platform/atlas-vector-search
- Opik (Observability): https://github.com/comet-ml/opik
Food for Thought
Beyond querying notes, what other personalized tasks could AI assistants handle within our ‘second brains’? What do you see as the biggest challenges in maintaining and scaling such a personalized AI system over time?
This post summarizes the first lesson of an open-source course by Paul Iusztin on Decoding ML.
Original Source: Iusztin, Paul. (2024, November 28). Build your Second Brain AI assistant. Decoding ML Substack. Retrieved from https://decodingml.substack.com/p/build-your-second-brain-ai-assistant?ref=dailydev